Traditional dialogue retrieval aims to select the most appropriate utterance or image from recent dialogue history. However, they often fail to meet users’ actual needs for revisiting semantically coherent content scattered across long-form conversations.
To fill this gap, we define the Fine-grained Fragment Retrieval (FFR) task, requiring models to locate query-relevant fragments, comprising both utterances and images, from multimodal long-form dialogues. As a foundation for FFR, we construct MLDR, the longest-turn multimodal dialogue retrieval dataset to date, averaging 25.45 turns per dialogue, with each naturally spanning three distinct topics. To evaluate generalization in real-world scenarios, we curate and annotate a WeChat-based test set comprising real-world multimodal dialogues with an average of 75.38 turns. Building on these resources, we explore existing generation-based Vision-Language Models (VLMs) on FFR and observe that they often retrieve incoherent utterance-image fragments. While optimized for generating responses from visual-textual inputs, these models lack explicit supervision to ensure semantic coherence within retrieved fragments. To address this, we propose F$^2$RVLM, a generative retrieval model trained in a two-stage paradigm: (1) supervised fine-tuning to inject fragment-level retrieval knowledge, and (2) GRPO-based reinforcement learning with multi-objective rewards to encourage outputs with semantic precision, relevance, and contextual coherence. In addition, to account for difficulty variations arising from differences in intra-fragment element distribution, ranging from locally dense to sparsely scattered, we introduce a difficulty-aware curriculum sampling that ranks training instances by predicted difficulty and gradually incorporates harder examples. This strategy enhances the model’s reasoning ability in long, multi-turn dialogue contexts. Experiments on both in-domain and real-domain sets demonstrate that F$^2$RVLM substantially outperforms popular VLMs, achieving superior retrieval performance.

Figure 1: Comparison between traditional Dialogue Retrieval and our Fine-grained Fragment Retrieval (FFR) task.
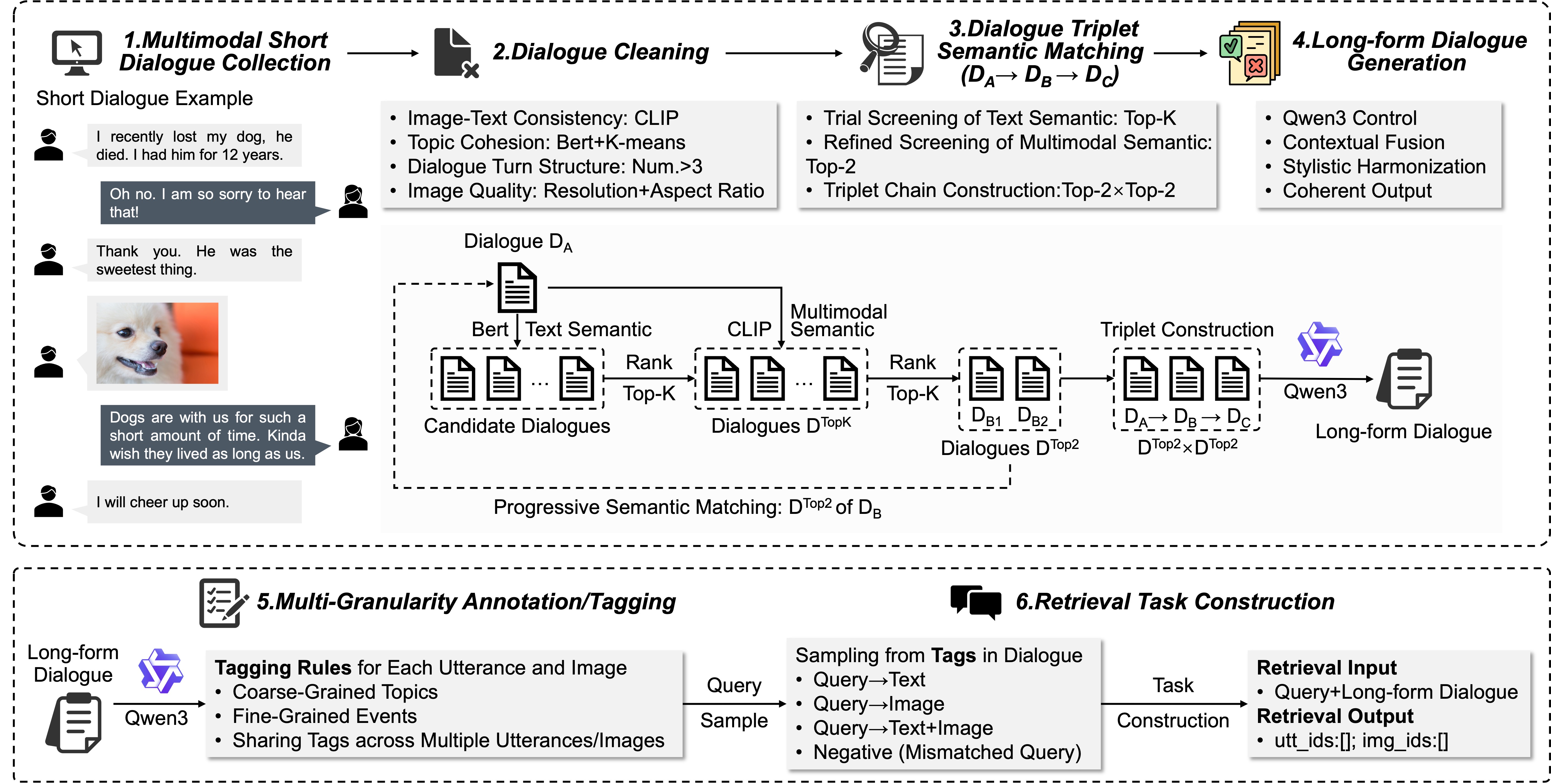
Figure 2: Overview of the MLDR construction pipeline, which integrates multimodal short dialogue processing, Qwen3-driven long-form dialogue generation, multi-granularity annotation, and retrieval-oriented task design.
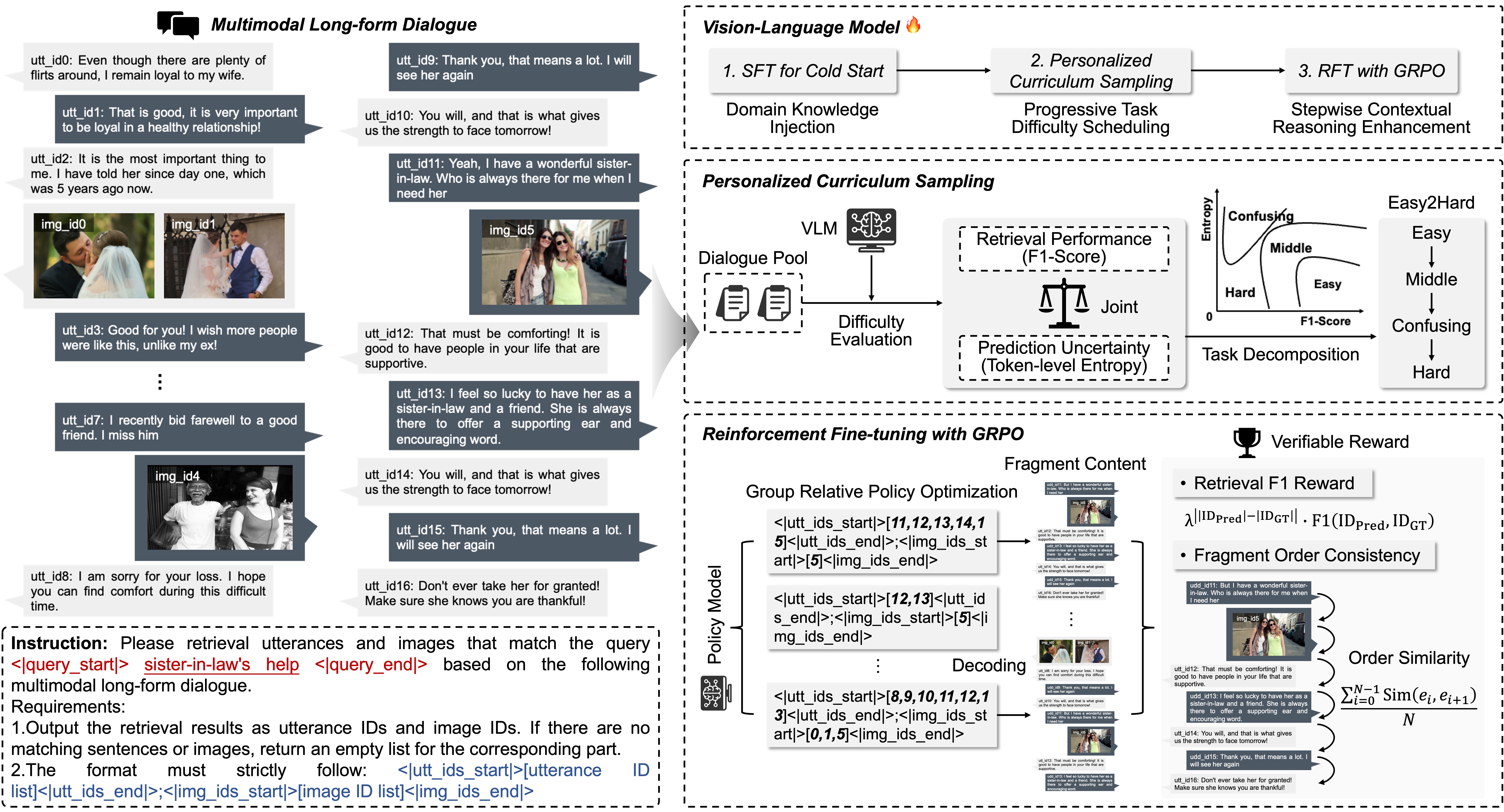
Figure 3: Overview of the F$^2$RVLM framework for multimodal long-form dialogue fragment retrieval. It consists of supervised fine-tuning for fragment-level knowledge injection, personalized curriculum sampling based on retrieval difficulty, and GRPO-based reinforcement learning to jointly enhance retrieval accuracy and fragment semantic coherence.
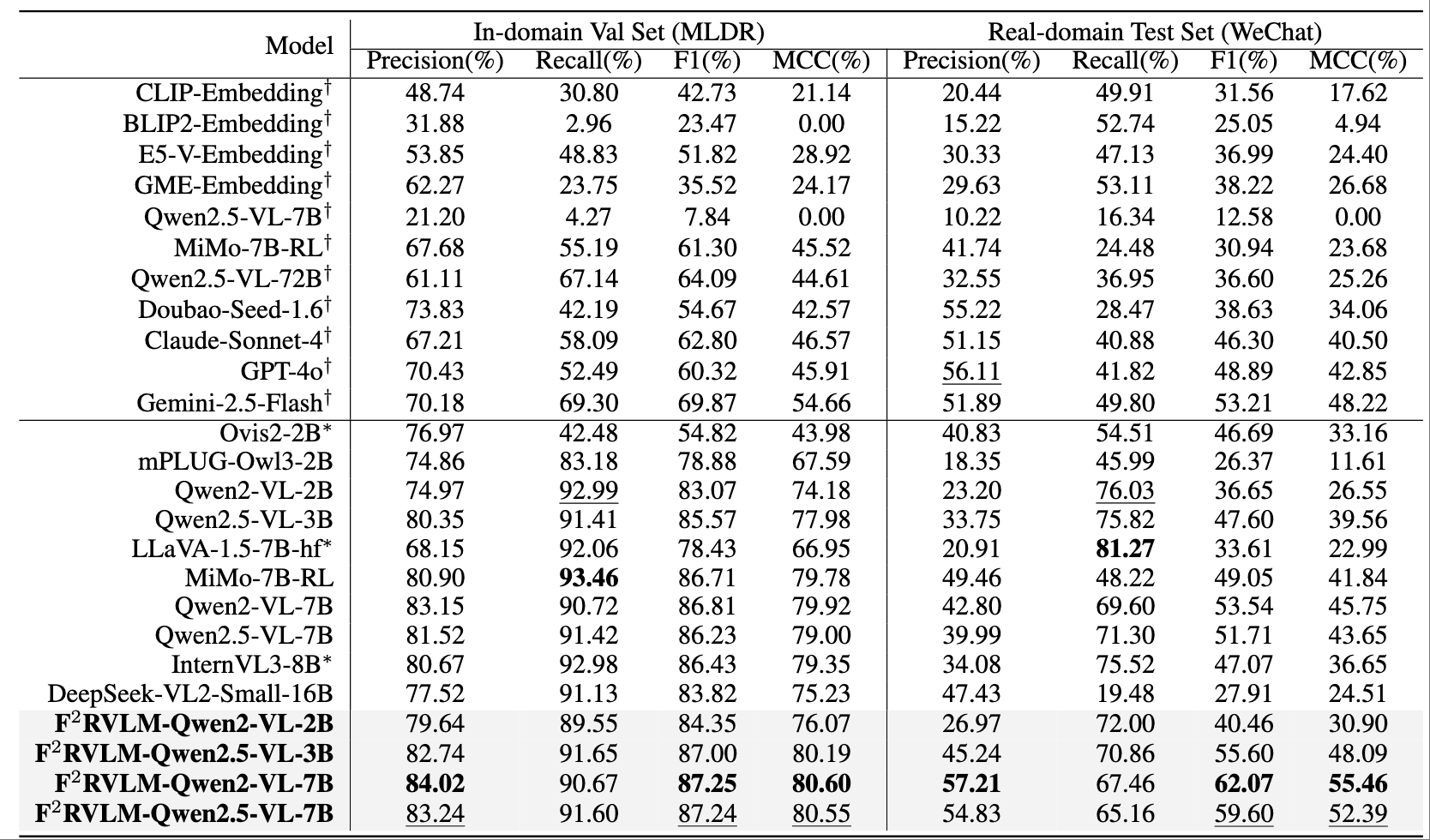
Table 1: Comparison with popular VLMs on the MLDR validation set and WeChat test set. ``$\dagger$'' indicates zero-shot inference without MLDR fine-tuning. ``$\ast$'' indicates models limited by context length, evaluated via sliding-window inference.
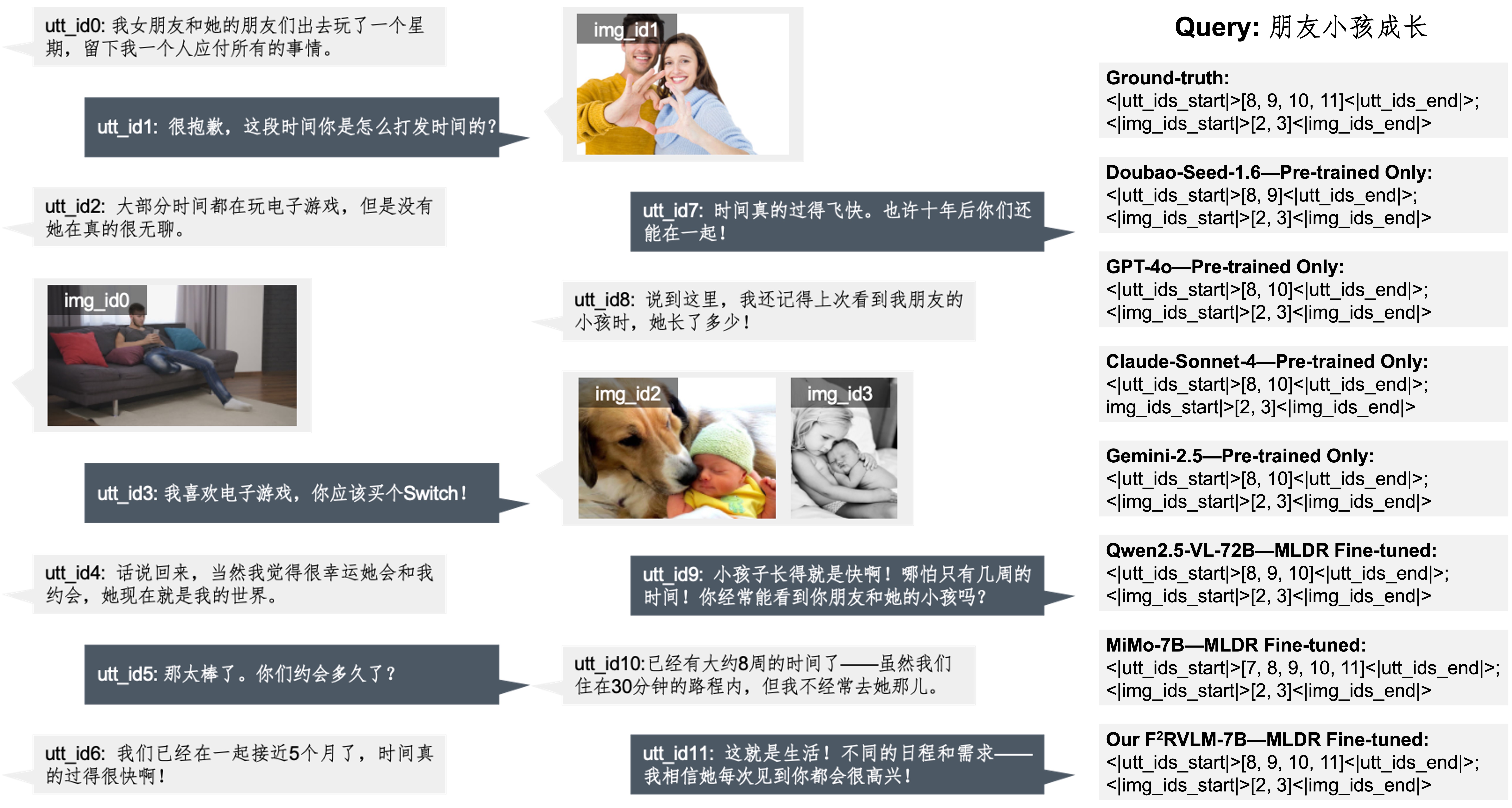
Figure 4: Qualitative comparison on the MLDR validation set. Given a user query, we visualize one representative case of retrieved fragments from various models. Pre-trained models often retrieve semantically relevant but incomplete or disjointed fragments. MLDR fine-tuned models improve alignment but may still miss contextual boundaries. Our F$^2$RVLM-7B achieves the most coherent and complete retrieval, accurately aligning both utterances and images with the intended semantics.

Figure 5: Case 1 of qualitative comparison on the WeChat test set.
Figure 6: Case 2 of qualitative comparison on the WeChat test set.
If you use our work in your research, please cite:
@misc{anonymous2025F2RVLM,
title={F²RVLM: Boosting Fine-grained Fragment Retrieval for Multi-Modal Long-form Dialogue with Vision Language Model},
author={Anonymous},
archivePrefix={arXiv},
primaryClass={cs.CV}}